xgboost与GBDT类似都是一种boosting方法,在之前写GBDT的时候有介绍过一点xgboost的思想,这里认真研究一下。
1. 1. xgboost原理
Adaboost算法是模型为加法模型的、损失函数为指数函数的、学习方法为前向分布算法的二分类问题。— from本站《Adaboost》博客
xgboost同样也是加法模型、损失函数可以是不同类型的convex函数、学习方法为前向分布算法。继续借用这三点来解释xgboost:
1.1. 1.1 加法模型
xgboost是由m个基模型组成的加法模型,假设第t次迭代要训练的基模型(e.g.决策树)是$f_t(x)$,则
即对于任意样本$i$,第t次迭代后的预测值=前t-1颗树的预测值+第t棵树的预测值。
注意:在GBDT一文中,$f(x)$表示的是前m轮迭代后的累积值,本文中的$f(x)$表示当前一轮迭代的预测值。
1.2. 1.2 目标函数:正则化&泰勒展开
[1] 模型的预测精度由模型的偏差和方差共同决定,损失函数代表了模型的偏差,想要方差小则需要在目标函数中添加正则项,用于防止过拟合。
xgboost的一大改进是在目标函数中加入正则项,防止模型过拟合。损失函数可以广义的定义为$\sum\limits_{i=1}^nl(y_i,\hat{y_i})$,那么目标函数可定义为
另一个改进是损失函数的泰勒展开:加法模型$\hat{y}_i^{(t)}= \hat{y}_i^{(t-1)} + f_t(x_i)$,预测值的增量即为$f_t(x_i)$,变化后的预测值对目标函数的影响为
第t步迭代的时候只关心变量$f_t(x_i)$,t-1步之前的都是已知量,所以$\sum\limits_{k=1}^{t-1}\Omega(f_k)$看作常数。损失函数增加了$f_t(x_i)$,使用泰勒展开:
得到样本i在第t的迭代之后的预测值:
其中$g_i$为损失函数在$\hat{y_i}^{(t-1)}$点的一阶导,$h_i$为损失函数在$\hat{y_i}^{(t-1)}$点的二阶导。总结一下:泰勒展开是关于损失函数,求导是对上一轮迭代的预测值求一阶、二阶导数。目标函数可写为
因为第t步时$\hat{y_i}^{(t-1)}$是已知值,所以$l(y_i, \hat{y_i}^{t-1})$可看作常数
constant项在下文可忽略,因为极小化目标函数$Obj^{(t)}$,就是找到第t步最优的变量$f_t(x_i)$(训练出一棵树$f_t$)。最后通过加法模型得到整体模型。
1.3. 1.3 前向分布:学习过程
虽然xgboost基模型不仅支持决策树,还支持线性模型,这里是介绍树模型。
在第t步,如何学习到一棵树$f_t$:树的结构、叶子节点对应的权重。
1.3.1. 定义一棵树
- 样本与叶子节点的mapping关系q
- 叶子节点的权重w
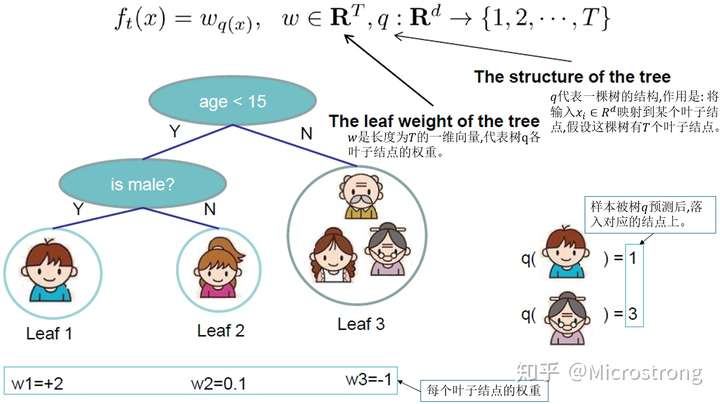
1.3.2. 定义树之后的目标函数
叶子节点归组:一棵树$f_t$确定之后,样本对应的叶子节点就确定了。若干条样本,会在有限个叶子节点中取值,$f_t(x_i) = w_{q(x_i)}$. 依照上图定义一棵树总共有T个叶子节点,令所有属于叶子节点$j$的样本$x_i$集合为$I_j={i | q(x_i)=j}$,所有属于$I_j$的样本取值均为$w_j$.
树的复杂度:复杂度由叶子数T和权重w组成,希望树不要有过多的叶子节点,并且节点的不具有过高的权重。
结合以上2点变化,把样本点按照叶子节点归组,目标函数可以写成
$G_j=\sum\limits_{i\in I_j}g_i$是叶子节点j包含的所有样本的一阶导数之和,一阶导数是$\left.\frac{\partial l(y_i,y)}{\partial y}\right|_{\hat{y_i}^{(t-1)}}$,是t-1步得到的结果;
$H_j=\sum\limits_{i\in I_j}h_i$是叶子节点j包含的所有样本的二阶导数之和,一阶导数是$\left.\frac{\partial^2 l(y_i,y)}{\partial y^2}\right|_{\hat{y_i}^{(t-1)}}$,也是t-1步得到的结果。
这样目标函数的表达式,只有w是未知变量,其余都是t-1步后已知,是关于w的一元二次表达式。[3]只要目标函数是凸函数,即二阶导数$H_j>0$,可以保证一元二次表达式的二次项>0,目标函数取到最小值。
对每个叶子节点j,与j有关的目标函数的部分为$G_jw_j+\frac{1}{2}(H_j+\lambda)w_j^2$. 因为叶子节点相互独立,每个叶子节点对应的目标函数达到最小值,整个目标函数$Obj^{(t)}$就达到最小值。可求得节点j的最优权重$w_j=-\frac{G_j}{H_j+\lambda}$,树$f_t$的目标函数值(对树结构$f_t$打分)为
1.3.3. 如何得到最优的树
在确定一颗树之后,可以求得这棵树的最优权重值以及目标函数值,如何确定最优的树呢?一棵树从一个节点(树深为0)开始,逐渐划分节点,生长成新的树。关键就是在每次划分节点的时候,找到最好的划分方式。
在树的生成过程中,如何判断当前叶子节点是否应该分裂?用分裂收益来衡量:
如果某个叶子节点完成分裂,分裂前的目标函数为$Obj_1 = -\frac{1}{2}[\frac{(G_L+G_R)^2}{H_L+H_R+\lambda}]+\gamma$;分裂成左右两个分支之后的目标函数为$Obj_2=-\frac{1}{2}[\frac{G_L^2}{H_L+\lambda}+\frac{G_R^2}{H_R+\lambda}]+\gamma$. 则分裂后的收益为$Gain=Obj_1-Obj_2$:
Gain越大,说明分裂之后目标函数减小量越大。注意,分裂收益也可作为feature importance的依据。
在树的生成过程中,样本的一阶、二阶导数只需要事先计算一次,在计算单个节点Obj的时候,只需将节点上对应的样本导数值求和得到不同的G和H。
贪婪算法:
- 初始树的深度为0
- 对叶子节点j:
- 枚举这个叶子节点的所有可用特征;
- 对每个特征,对属于这个叶子节点的样本,按照特征的取值升序排列;
- 计算每个特征取值分裂得到的分裂收益,选择分裂收益最大的,作为最优分裂特征的分裂位置
- 从所有节点上按照第2步找到最优分裂位置,分裂出左右两个新的叶子节点,并将j的样本分配到这两个节点上
- 递归执行节点分裂,直到满足终止条件
选取叶子节点进行分裂的顺序不重要,递归的进行即可。贪婪算法的每次分裂,都要枚举所有特征的所有可能分裂方案。将特征取值排序之后,计算按照不同取值进行分裂会变得很简单,因为梯度已经计算好,只需要简单的加减法就可以得到分裂的$G_L, G_R, H_L, H_R$,从而计算出Gain。节点的划分不一定会使Gain一直都>0,因为有引入新叶子的正则惩罚项。如果分裂带来的Gain小于某个阈值,则剪掉该分裂。
近似算法:
贪婪算法可以得到最优解$f_t$,但是当数据量太大时内存会爆,这时可用近似算法,减少计算复杂度。
对某节点的每个特征,不枚举所有的取值,只考虑某些分位点。根据特征取值的分布,提出候选分位点,然后在这些候选分位点上分裂。
- Global:学习每棵树前,确定分位点,每次分裂时都采用这种分裂;
- Lobal:每次分裂前重新制定候选分位点
[1] Global 策略在候选点数多时(eps 小)可以和 Local 策略在候选点少时(eps 大)具有相似的精度。此外我们还发现,在eps取值合理的情况下,分位数策略可以获得与贪心算法相同的精度。

第一个for循环对每个特征k确定分裂用的候选分位点$S_k$;第二个for循环对每个由分位数划分成的区间进行G和H的累加,方便了得到每个特征的候选分位点对应的G、H值。
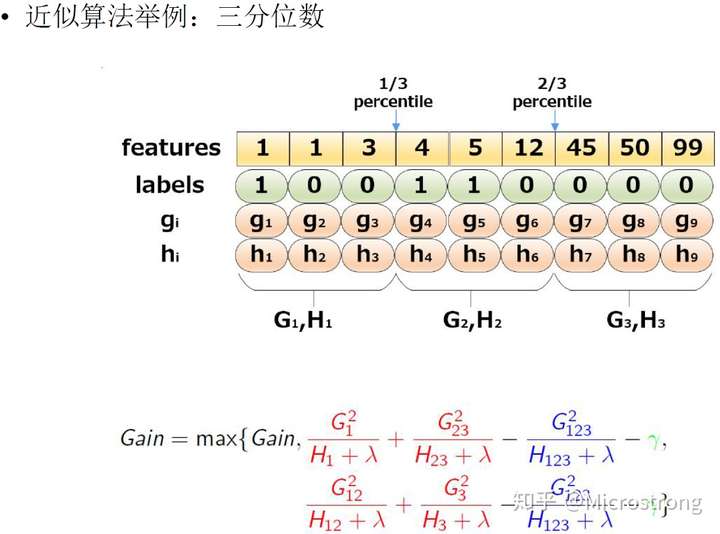
上图的例子中,只针对某一个特征,取1/3、2/3分位点来作为候选。(s1, s2+s3), (s1+s2, s3)和s1+s2+s3来比较。
xgboost不是简单的按照样本的个数来分位,而且用$h_i$作为样本权重进行分位,作者设计了weighted quantile sketch算法。为什么用二阶梯度$h_i$作为权重,参见[1].
2. 2. 一些细节
2.1. 2.1 缺失值
一些设计对样本距离的度量的模型,如SVM和KNN,加入缺失值处理不当,最终导致模型预测效果很差。不过xgboost对缺失值不敏感,树模型对缺失值的敏感度都比较低。
因为xgboost在构建树,即在某特征上寻找分裂点时,不考虑缺失样本,只考虑对非缺失数据的样本进行遍历,但同时对每个节点增加了一个缺失值方向(依然是二叉树)。剩下那些缺失值样本,把它们统一打包归组到左叶子节点和右叶子节点,然后再选分裂收益大的那个,作为预测时缺失特征的分裂方向。如果训练集没有缺失值,测试集有,那么默认将缺失值划分到右叶子节点方向。
2.2. 2.2 feature importance
- gain: 以这个特征分裂之后,得到的gain在所有树上的平均值
- weight:该特征在所有树中被用作分裂节点的总次数
- cover:该特征在其出现过的所有树中的平均覆盖范围。覆盖范围指一个特征用作分裂点之后,其影响的样本数量,即有多少样本经过该特征分裂到两个子节点。
2.3. 2.3 并行
xgboost的并行,不是每棵树并行训练,xgboost依然是boosting思想,一棵树训练完才行训练下一颗。
xgboost的并行,是指特征维度的并行:在训练之前,每个特征按取值对样本预排序,用稀疏矩阵格式存储为block结构,在block里面保存排序后的特征值及对应样本的引用,以便于获取样本的一阶、二阶导数值。在后面训练过程中(查找分裂点时)可重复使用block结构:在同一棵树的生成过程中,样本对应的一阶、二阶导数值不变,计算不同节点分裂收益时,只需要将block进行组合即可。
每个特征都可以独立的进行预排序和分block,所以对同一个节点选择哪个特征的分裂收益最大时,可以对多个特征并行运算。
2.4. 2.4 subsampling
xgboost支持行采样,setting subsampling=0.5 means that XGBoost would randomly sample half of the training data prior to growing trees. and this will prevent overfitting. Subsampling will occur once in every boosting iteration.
xgboost还支持列抽样, subsample ratio of columns when constructing each tree. Subsampling occurs once for every tree constructed.
2.5. 2.5 Hessian矩阵
为什么会牵扯到Hessian矩阵?牛顿法的思想:对损失函数泰勒展开到二阶导数,求极值得到牛顿下降方向 $-H^{-1}g$;类似地,xgboost也可以通过求牛顿方向来得到$f_t$,这样就需要求Hessian矩阵的逆了。牛顿法的牛顿方向对应于xgboost每一次迭代的增加量$f_t$.
在xgboost这里,Hessian矩阵很特殊,是一个对角阵,容易计算。如果不考虑正则项,$Obj^{(t)}_i\approx l(y_i,\hat{y_i}^{t-1})+g_if_t(x_i)+\frac{1}{2}h_if^2_t(x_i)$,样本之间没有cross,所以Hessian矩阵是对角阵,如果把n个样本看成n维向量,nxn维的Hessian对角矩阵,牛顿方向$-H^{-1}g$.
但xgboost的目标函数有所不同,存在正则项,正则项也包含需要优化的变量w,经过节点的归组,$Obj^{(t)}_j\approx G_jw_{j}+\frac{1}{2}(H_j+\lambda)w^2_{j}+\gamma$,类似地把T个节点看成T维向量,则有TxT维的Hessian对角矩阵,$w^*=-(H+\lambda)^{-1}G$,在形式上与上文使用的方法一致。
2.6. 2.6 工程实现
列块并行学习、缓存访问、核外块计算
2.7. 2.7 remaining questions
- xgboost梯度的维度?不同样本的梯度是分开求的,每个样本求一次和二次导数,所以维度是:迭代数x样本数x2
- 上文默认的基模型应该是
gbtree,另外还有gblinear和dart。gblinear是线性模型,dart是带dropout的树模型。 - xgboost如何处理分类问题?思路应该与GBDT相同,可参考GBDT一文。以二分类问题为例,损失函数为logloss,拟合后的值,需要经过logistic函数来转化为取值为1的概率,所以拟合的是概率的残差,最终的输出值为$P(y_i=1|x_i)=\frac{1}{1+e^{-\hat{y}_i^{(M)}}}$.
3. 3. xgboost与GBDT
xgboost和GBDT都在拟合残差,之所以是拟合残差,可以从泰勒展开的角度理解。导数都是上一轮的预测值关于损失函数的导数。都是加法模型,上一轮的预测值,加上这一轮的拟合结果,等于这一轮的预测值。
最重要的不同,是xgboost使用一阶和二阶导数来拟合残差,GBDT只使用一阶导数。训练树的过程也不同,GBDT用的是CART;而xgboost多考虑了正则项、使用不同的Gain生长树(分裂收益 v.s. Gini index)、获取叶子节点权重的方式也不同($w_j=-\frac{G_j}{H_j+\lambda}$ v.s. line search),xgboost中默认的基模型为gbtree(上文整个推导过程)。可以看出,gbtree与CART是不同的。
3.1. 3.1 xgboost的优点 [1]
- 精度更高:GBDT 只用到一阶泰勒展开,而 xgboost 对损失函数进行了二阶泰勒展开。XGBoost 引入二阶导一方面是为了增加精度,另一方面也是为了能够自定义损失函数,二阶泰勒展开可以近似大量损失函数;
- 灵活性更强:GBDT 以 CART 作为基分类器,xgboost 不仅支持树模型还支持线性分类器,使用线性分类器的 xgboost 相当于带 L1 和 L2 正则化项的逻辑斯蒂回归(分类问题)或者线性回归(回归问题)。此外,xgboost 工具支持自定义损失函数,只需函数支持一阶和二阶求导;
- 正则化:xgboost 在目标函数中加入了正则项,用于控制模型的复杂度。正则项里包含了树的叶子节点个数、叶子节点权重的 L2 范式。正则项降低了模型的方差,使学习出来的模型更加简单,有助于防止过拟合,提高泛化能力,这也是xgboost优于传统GBDT的一个特性。
- Shrinkage(缩减):相当于学习速率。xgboost 在进行完一次迭代后,会将叶子节点的权重乘上该系数,主要是为了削弱每棵树的影响,让后面有更大的学习空间。传统GBDT的实现也有学习速率;
- 子采样&列抽样:xgboost 借鉴了随机森林的做法,支持行采样、列抽样,不仅能降低过拟合,还能减少计算。这也是xgboost异于传统GBDT的一个特性;
- 缺失值处理:对于特征的值有缺失的样本,xgboost 采用的稀疏感知算法可以自动学习出它的分裂方向;
- XGBoost工具支持并行:注意xgboost的并行不是tree粒度的并行,xgboost也是一次迭代完才能进行下一次迭代的(第t次迭代的代价函数里包含了前面t-1次迭代的预测值)。xgboost的并行是在特征粒度上的。我们知道,决策树的学习最耗时的一个步骤就是对特征的值进行排序(因为要确定最佳分割点),xgboost在训练之前,预先对每个特征按照特征值排序,保存为block结构,后面的迭代中重复地使用这个结构,大大减小计算量。这个block结构也使得并行成为了可能,在进行节点的分裂时,需要计算每个特征的增益,最终选增益最大的那个特征去做分裂,那么各个特征的增益计算就可以开多线程进行。
- 可并行的近似算法:树节点在进行分裂时,我们需要计算每个特征的每个分割点对应的增益,即用贪心法枚举所有可能的分割点。当数据无法一次载入内存或者在分布式情况下,贪心算法效率就会变得很低,所以xgboost还提出了一种可并行的近似算法,用于高效地生成候选的分割点。
3.2. 3.2 xgboost的缺点 [1]
- 虽然利用预排序和近似算法可以降低寻找最佳分裂点的计算量,但在节点分裂过程中仍需要遍历数据集;
- 预排序过程的空间复杂度过高,不仅需要存储特征值,还需要存储特征对应样本的梯度统计值的索引,相当于消耗了两倍的内存。